Performance¶

Unicon performance¶
Unicon is a very high level language. The runtime engine, with generators, co-expressions, threading, and the assortment of other features means that most operations need to include a fair number of conditional tests to verify correctness. While this is some overhead, Unicon still performs at a very respectable level. The C compilation mode can help when performance is a priority, and loadfunc is always available when C or Assembly level speed is necessary for critical operations.
Unicon, interpreting icode files, ranges from 20 to 40 times slower
than optimized C code in simple loops and straight up computations. On par
with similar code in Python. Compiled Unicon (via unicon -C) is probably
about 10 times slower than similar C when timing a tight numeric computation
loop. This is mainly due to the overhead that is required for the very high
level language features of Unicon, mentioned above.
As always, those are somewhat unfair comparisons. The tasks that Unicon can be applied to and the development time required to get correct solutions can easily outweigh a few seconds of runtime per program pass. Saving a week of effort can mean that many thousands of program runs are required before a developer hits a break even point. Five eight hours days total up 144,000 seconds. If the delta for a program run between C and Unicon is 5 seconds per run, you’d need to run a program over 28,000 times to make up for a one week difference in development time. Critical routines can leverage loadable functions when needed. All these factors have to be weighed when discussing performance issues.
With all that in mind, it’s still nice to have an overall baseline for daily tasks, to help decide when to bother with loadfunc or which language is the right tool for the task at hand[1].
| [1] | Or more explicitly; not the wrong tool for the task at hand. Most general purpose programming languages are capable of providing a workable solution to any computing problem, but sometimes the problem specific advantages in one language make it an obvious choice for mixing with Unicon for performance and or development time benefits. |
Note
This section is unashamedly biased towards Unicon. It’s the point of the exercise. All comparisons assume that point of view and initial bias.
Summing integers¶
Given a simple program, creating a sum of numbers in a tight loop. Comparing
Unicon with Python, and C.
Other scripting and compiled languages are included for general interest sake. This lists simple code running 16.8 million iterations while tallying a sum in each language.
Note
The representative timings below each listing are approximate, and results will vary from run to run. There is a fixed number included with each the listing to account for those times when the document generation may have occurred while the build system was blocked or busy at the point of timing run capture. Tested running Xubuntu with an AMD A10-5700 quadcore APU chipset. Different hardware would have different base values, but should have equivalent relative timings.
Unicon¶
Unicon, tightloop.icn
#
# tightloop trial, sum of values from 0 to 16777216
#
procedure main()
total := 0
every i := 0 to 2^24 do total +:= i
write(total)
end
Representative timing: 2.02 seconds, 0.55 seconds (-C compiled)
examples/performance/tightloop.icn
unicon (icode)
prompt$ time -p unicon -s tightloop.icn -x
140737496743936
real 2.26
user 2.24
sys 0.01
unicon -C
prompt$ unicon -s -o tightloop-uc -C tightloop.icn
prompt$ time -p ./tightloop-uc
140737496743936
real 0.61
user 0.61
sys 0.00
Python¶
Python, tightloop-py.py
# Sum of values from 0 to 16777216
total = 0
n = 2**24
for i in range(n, 1, -1):
total += i
print(total)
Representative timing: 2.06 seconds
examples/performance/tightloop-py.py
prompt$ time -p python tightloop-py.py
140737496743935
real 2.14
user 1.91
sys 0.22
C¶
C, tightloop-c.c
/* sum of values from 0 to 16777216 */
#include <stdio.h>
int
main(int argc, char** argv)
{
int i;
int n;
unsigned long total;
total = 0;
n = 1 << 24;
for (i = n; i > 0; i--)
total += i;
printf("%lu\n", total);
return 0;
}
Representative timing: 0.05 seconds
examples/performance/tightloop-c.c
prompt$ gcc -o tightloop-c tightloop-c.c
prompt$ time -p ./tightloop-c
140737496743936
real 0.05
user 0.05
sys 0.00
Ada¶
Ada, tightloopada.adb
-- Sum of values from 0 to 16777216
with Ada.Long_Long_Integer_Text_IO;
procedure TightLoopAda is
total : Long_Long_Integer;
begin
total := 0;
for i in 0 .. 2 ** 24 loop
total := total + Long_Long_Integer(i);
end loop;
Ada.Long_Long_Integer_Text_IO.Put(total);
end TightLoopAda;
Representative timing: 0.06 seconds
examples/performance/tightloopada.adb
GNAT Ada, 5.4.0
prompt$ gnatmake tightloopada.adb
gnatmake: "tightloopada" up to date.
prompt$ time -p ./tightloopada
140737496743936
real 0.06
user 0.06
sys 0.00
ALGOL¶
ALGOL, tightloop-algol.a68 [2]
# Sum of values from 0 to 16777216 #
BEGIN
INT i := 0;
LONG INT total := 0;
FOR i FROM 0 BY 1 TO 2^24 DO
total +:= i
OD;
print ((total))
END
Representative timing: 5.91 seconds
examples/performance/tightloop-algol.a68
prompt$ a68g tightloop-algol
+140737496743936
real 5.91
user 5.86
sys 0.03
Assembler¶
Assembler, tightloop-assembler.s
# Sum of integers from 0 to 16777216
.data
aslong: .asciz "%ld\n"
.text
.globl main
main:
push %rbp # need to preserve base pointer
movq %rsp, %rbp # local C stack, frame size 0
movq $0, %rax # clear out any high bits
movl $1, %eax # eax counts down from
shll $24, %eax # 2^24
movq $0, %rbx # rbx is the running total
top: addq %rax, %rbx # add in current value, 64 bit
decl %eax # decrement counter (as 32 bit)
jnz top # if counter not 0, then loop again
done: movq %rbx, %rsi # store sum in rsi for printf arg 2
lea aslong(%rip), %rdi # load format string address
call printf # output formatted value
movl $0, %eax # shell result code
leave
ret
Representative timing: 0.01 seconds
examples/performance/tightloop-assembler.s
prompt$ gcc -o tightloop-assembler tightloop-assembler.s
prompt$ time -p ./tightloop-assembler
140737496743936
real 0.01
user 0.01
sys 0.00
BASIC¶
BASIC, tightloop-basic.bac
REM Sum of values from 0 to 16777216
total = 0
FOR i = 0 TO 1<<24
total = total + i
NEXT
PRINT total
Representative timing: 0.05 seconds
examples/performance/tightloop-basic.bac
prompt$ bacon -y tightloop-basic.bac >/dev/null
prompt$ time -p ./tightloop-basic
140737496743936
real 0.05
user 0.05
sys 0.00
C (baseline)¶
See above, Unicon, C and Python are the ballpark for this comparison.
COBOL¶
COBOL, tightloop-cobol.cob
*> Sum of values from 0 to 16777216
identification division.
program-id. tightloop-cob.
data division.
working-storage section.
01 total usage binary-double value 0.
01 counter usage binary-long.
01 upper usage binary-long.
procedure division.
compute upper = 2**24
perform varying counter from 0 by 1 until counter > upper
add counter to total
end-perform
display total
goback.
end program tightloop-cob.
Representative timing: 0.06 seconds
examples/performance/tightloop-cobol.cob
GnuCOBOL 2.0-rc3
prompt$ cobc -x tightloop-cobol.cob
prompt$ time -p ./tightloop-cobol
+00000140737496743936
real 0.07
user 0.07
sys 0.00
D¶
D, tightloop-d.d
/* Sum of values from 0 to 16777216 */
module tightloop;
import std.stdio;
void
main(string[] args)
{
long total = 0;
for (int n = 0; n <= 1<<24; n++) total += n;
writeln(total);
}
Representative timing: 0.05 seconds
examples/performance/tightloop-d.d
gdc
prompt$ gdc tightloop-d.d -o tightloop-d
prompt$ time -p ./tightloop-d
140737496743936
real 0.05
user 0.05
sys 0.00
ECMAScript¶
ECMAScript, tightloop-js.js
/* Sum of values from 0 to 16777216 */
var total = 0;
for (var i = 0; i <= Math.pow(2,24); i++) total += i;
// Account for gjs, Seed, Duktape, Jsi
try { print(total); } catch(e) {
try { console.log(total); } catch(e) {
try { puts(total); } catch(e) {}
}
}
Representative timing: 0.83 seconds (node.js), 10.95 (gjs), 63.37 (duktape)
examples/performance/tightloop-js.js
nodejs
prompt$ time -p nodejs tightloop-js.js
140737496743936
real 0.78
user 0.77
sys 0.01
gjs [2]
prompt$ time -p gjs tightloop-js.js
140737496743936
real 10.96
user 10.95
sys 0.00
Duktape [2]
prompt$ time -p duktape tightloop-js.js
140737496743936
real 63.37
user 63.36
sys 0.00
Elixir¶
Elixir, tightloop-elixir.ex
# Sum of values from 0 to 16777216
Code.compiler_options(ignore_module_conflict: true)
defmodule Tightloop do
def sum() do
limit = :math.pow(2, 24) |> round
IO.puts Enum.sum(0..limit)
end
end
Tightloop.sum()
Representative timing: 2.03 seconds
examples/performance/tightloop-elixir.ex
elixirc 1.1.0-dev
prompt$ time -p elixirc tightloop-elixir.ex
140737496743936
real 2.11
user 2.13
sys 0.09
Forth¶
Forth, tightloop-ficl.fr
( Sum of values from 0 to 16777216)
variable total
: tightloop ( -- ) 1 24 lshift 1+ 0 do i total +! loop ;
0 total ! tightloop total ? cr
bye
Representative timing: 0.52 seconds (Ficl), 0.12 seconds (Gforth)
examples/performance/tightloop-ficl.fr
ficl
prompt$ time -p ficl tightloop-ficl.fr
140737496743936
real 0.50
user 0.50
sys 0.00
gforth
prompt$ time -p gforth tightloop-ficl.fr
140737496743936
real 0.09
user 0.09
sys 0.00
Fortran¶
Fortran, tightloop-fortran.f
! sum of values from 0 to 16777216
program tightloop
use iso_fortran_env
implicit none
integer :: i
integer(kind=int64) :: total
total = 0
do i=0,2**24
total = total + i
end do
print *,total
end program tightloop
Representative timing: 0.06 seconds
examples/performance/tightloop-fortran.f
gfortran
prompt$ gfortran -o tightloop-fortran -ffree-form tightloop-fortran.f
prompt$ time -p ./tightloop-fortran
140737496743936
real 0.06
user 0.06
sys 0.00
Groovy¶
Groovy, tightloop-groovy.groovy
/* Sum of value from 0 to 16777216 */
public class TightloopGroovy {
public static void main(String[] args) {
long total = 0;
for (int i = 0; i <= 1<<24; i++) {
total += i
}
println(total)
}
}
Representative timing: 0.47 seconds (will use multiple cores)
examples/performance/tightloop-groovy.groovy
groovyc 1.8.6, OpenJDK 8
prompt$ groovyc tightloop-groovy.groovy
prompt$ time -p java -cp ".:/usr/share/groovy/lib/*" TightloopGroovy
140737496743936
real 0.63
user 1.29
sys 0.07
Java¶
Java, tightloopjava.java
/* Sum of values from 0 to 16777216 */
public class tightloopjava {
public static void main(String[] args) {
long total = 0;
for (int n = 0; n <= Math.pow(2, 24); n++) {
total += n;
}
System.out.println(total);
}
}
Representative timing: 0.11 seconds
examples/performance/tightloopjava.java
OpenJDK javac
prompt$ javac tightloopjava.java
prompt$ time -p java -cp . tightloopjava
140737496743936
real 0.67
user 0.79
sys 0.02
Lua¶
Lua, tightloop-lua.lua
-- Sum of values from 0 to 16777216
total = 0
for n=0,2^24,1 do
total = total + n
end
print(string.format("%d", total))
Representative timing: 0.73 seconds
examples/performance/tightloop-lua.lua
lua
prompt$ time -p lua tightloop-lua.lua
140737496743936
real 0.72
user 0.72
sys 0.00
Neko¶
Neko, tightloop-neko.neko
// Sum of values from 0 to 16777216
var i = 0;
var total = 0.0;
var limit = 1 << 24;
while i <= limit {
total += i;
i += 1;
}
$print(total, "\n");
Representative timing: 0.89 seconds
examples/performance/tightloop-neko.neko
nekoc, neko
prompt$ nekoc tightloop-neko.neko
prompt$ time -p neko tightloop-neko
140737496743936
real 0.95
user 1.06
sys 0.14
Nickle¶
Nickle, tightloop-nickle.c5
/* Sum of values from 0 to 16777216 */
int total = 0;
int n = 1 << 24;
for (int i = n; i > 0; i--) {
total += i;
}
printf("%g\n", total);
4.85 seconds representative
examples/performance/tightloop-nickle.c5
Nickle 2.77 [2]
prompt$ time -p nickle tightloop-nickle.c5
140737496743936
real 4.85
user 4.83
sys 0.01
Nim¶
Nim, tightloopNim.nim
# Sum of values from 0 to 16777216
var total = 0
for i in countup(0, 1 shl 24):
total += i
echo total
Representative timing: 0.31 seconds
examples/performance/tightloopNim.nim
nim
prompt$ nim compile --verbosity:0 --hints:off tightloopNim.nim
prompt$ time -p ./tightloopNim
140737496743936
real 0.31
user 0.30
sys 0.00
Perl¶
Perl, tightloop-perl.pl
# sum of values from 0 to 16777216
my $total = 0;
for (my $n = 0; $n <= 2 ** 24; $n++) {
$total += $n;
}
print "$total\n";
Representative timing: 1.29 seconds
examples/performance/tightloop-perl.pl
perl 5.22
prompt$ time -p perl tightloop-perl.pl
140737496743936
real 1.31
user 1.31
sys 0.00
PHP¶
PHP, tightloop-php.php
<?php
# Sum of values from 0 to 16777216
$total = 0;
for ($i = 0; $i <= 1 << 24; $i++) {
$total += $i;
}
echo $total.PHP_EOL;
?>
Representative timing: 0.39 seconds
examples/performance/tightloop-php.php
PHP 7.0.15, see PHP.
prompt$ time -p php tightloop-php.php
140737496743936
real 0.42
user 0.41
sys 0.00
Python¶
See above. Unicon, C and Python are the ballpark for this comparison.
REBOL¶
REBOL, tightloop-rebol.r
; Sum of values from 0 to 16777216
REBOL []
total: 0
for n 0 to integer! 2 ** 24 1 [total: total + n]
print total
2.22 seconds representative
examples/performance/tightloop-rebol.r3
r3
prompt$ time -p r3 tightloop-rebol.r3
140737496743936
real 2.83
user 2.22
sys 0.01
REXX¶
REXX, tightloop-rexx.rex
/* Sum of integers from 0 to 16777216 */
parse version host . .
parse value host with 6 which +6
if which = "Regina" then
numeric digits 16
total = 0
do n=0 to 2 ** 24
total = total + n
end
say total
2.38 seconds representative (oorexx), 4.48 (regina)
examples/performance/tightloop-rexx.rex
oorexx 4.2
prompt$ time -p /usr/bin/rexx tightloop-rexx.rex
140737496743936
real 2.47
user 2.45
sys 0.01
regina 3.9, slowed by NUMERIC DIGITS 16 for clean display [2]
prompt$ time -p rexx tightloop-rexx.rex
140737496743936
real 4.84
user 4.84
sys 0.00
Ruby¶
Ruby, tightloop-ruby.rb
# Sum of values from 0 to 16777216
total = 0
for i in 0..2**24
total += i
end
puts(total)
Representative timing: 1.16 seconds
examples/performance/tightloop-ruby.rb
ruby 2.3
prompt$ time -p ruby tightloop-ruby.rb
140737496743936
real 1.13
user 1.13
sys 0.00
Rust¶
Rust, tightloop-rust.rs
// sum of values from 0 to 16777216
fn main() {
let mut total: u64 = 0;
for i in 0..1<<24 {
total += i;
}
println!("{}", total);
}
Representative timing: 0.44 seconds
examples/performance/tightloop-rust.rs
rustc 1.16.0
prompt$ /home/btiffin/.cargo/bin/rustc tightloop-rust.rs
prompt$ time -p ./tightloop-rust
140737479966720
real 0.37
user 0.37
sys 0.00
Scheme¶
Scheme, tightloop-guile.scm
; sum of values from 0 to 16777216
(define (sum a b)
(do ((i a (+ i 1))
(result 0 (+ result i)))
((> i b) result)))
(display (sum 0 (expt 2 24)))
(newline)
Representative timing: 0.85 seconds
examples/performance/tightloop-guile.scm
guile 2.0.11
prompt$ time -p guile -q tightloop-guile.scm
140737496743936
real 1.00
user 0.99
sys 0.01
Shell¶
Shell, tightloop-sh.sh
# Sum of integers from 0 to 16777216
i=0
total=0
while [ $i -le $((2**24)) ]; do
let total=total+i
let i=i+1
done
echo $total
Representative timing: 281.29 seconds
examples/performance/tightloop-sh.sh
bash 4.3.46 [2]
prompt$ time -p source tightloop-sh.sh
140737496743936
real 281.29
user 280.08
sys 1.11
S-Lang¶
S-Lang, tightloop-slang.sl
% Sum of values from 0 to 16777216
variable total = 0L;
variable i;
for (i = 0; i <= 1<<24; i++)
total += i;
message(string(total));
Representative timing: 4.92 seconds
examples/performance/tightloop-slang.sl
slsh 0.9.1 with S-Lang 2.3 [2]
prompt$ time -p slsh tightloop-slang.sl
140737496743936
real 4.92
user 4.92
sys 0.00
Smalltalk¶
Smalltalk, tightloop-smalltalk.st
"sum of values from 0 to 16777216"
| total |
total := 0
0 to: (1 bitShift: 24) do: [:n | total := total + n]
(total) printNl
Representative timing: 4.60 seconds
examples/performance/tightloop-smalltalk.st
GNU Smalltalk 3.2.5 [2]
prompt$ time -p gst tightloop-smalltalk.st
140737496743936
real 4.56
user 4.55
sys 0.00
SNOBOL¶
SNOBOL, tightloop-snobol.sno
* Sum of values from 0 to 16777216
total = 0
n = 0
loop total = total + n
n = lt(n, 2 ** 24) n + 1 :s(loop)
output = total
end
Representative timing: 5.83 seconds
examples/performance/tightloop-snobol.sno
snobol4 CSNOBOL4B 2.0 [2]
prompt$ time -p snobol4 tightloop-snobol.sno
140737496743936
real 5.83
user 5.82
sys 0.00
Tcl¶
Tcl, tightloop-tcl.tcl
# Sum of values from 0 to 16777216
set total 0
for {set i 0} {$i <= 2**24} {incr i} {
incr total $i
}
puts "$total"
Representative timing: 4.59 seconds (jimsh), 17.69 seconds (tclsh)
examples/performance/tightloop-tcl.tcl
jimsh 0.76 [2]
prompt$ time -p jimsh tightloop-tcl.tcl
140737496743936
real 4.59
user 4.59
sys 0.00
tclsh 8.6 [2]
prompt$ time -p tclsh tightloop-tcl.tcl
140737496743936
real 17.69
user 17.67
sys 0.00
Vala¶
Vala, tightloop-vala.vala
/* Sum of values from 0 to 16777216 */
int main(string[] args) {
long total=0;
for (var i=1; i <= 1<<24; i++) total += i;
stdout.printf("%ld\n", total);
return 0;
}
Representative timing: 0.16 seconds
examples/performance/tightloop-vala.vala
valac 0.34.2
prompt$ valac tightloop-vala.vala
prompt$ time -p ./tightloop-vala
140737496743936
real 0.10
user 0.10
sys 0.00
Genie¶
Vala/Genie, tightloop-genie.gs
/* Sum of values from 0 to 16777216 */
[indent=4]
init
total:long = 0
for var i = 1 to (1<<24)
total += i
print("%ld", total)
Representative timing: 0.16 seconds
examples/performance/tightloop-genie.gs
valac 0.34.2
prompt$ valac tightloop-genie.gs
prompt$ time -p ./tightloop-genie
140737496743936
real 0.10
user 0.10
sys 0.00
Unicon loadfunc¶
A quick test for speeding up Icon
Unicon loadfunc, tightloop-loadfunc.icn
#
# tightloop trial, sum of values from 0 to 16777216
#
procedure main()
faster := loadfunc("./tightloop-cfunc.so", "tightloop")
total := faster(2^24)
write(total)
end
Representative timing: 0.05 seconds
examples/performance/tightloop-loadfunc.icn
C loadfunc for Unicon, tightloop-cfunc.c
/* sum of values from 0 to integer in argv[1] */
#include "../icall.h"
int
tightloop(int argc, descriptor argv[])
{
int i;
unsigned long total;
ArgInteger(1);
total = 0;
for (i = 0; i <= IntegerVal(argv[1]); i++) total += i;
RetInteger(total);
}
examples/performance/tightloop-cfunc.c
unicon with loadfunc
prompt$ gcc -o tightloop-cfunc.so -O3 -shared -fpic tightloop-cfunc.c
prompt$ time -p unicon -s tightloop-loadfunc.icn -x
140737496743936
real 0.04
user 0.02
sys 0.01
Summary¶
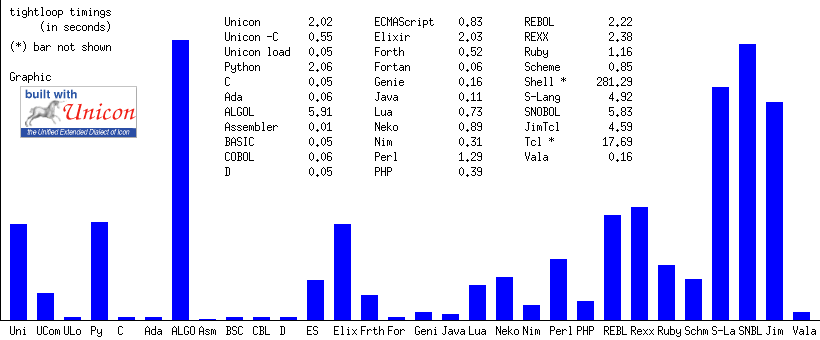
In the image above, bars for Bash shell and Tclsh are not included. ECMAScript value is from Node.js (V8). [3]
There was no attempt to optimize any code. Compile times are only included when that is the normal development cycle. Etcetera. Routines can always be optimized, tightened, and fretted over. The point of this little exercise is mainly for rough guidance (perhaps with healthy doses of confirmation, self-serving, halo effect, academic, and/or experimenters bias [8]). [4]
While there may be favouritism leaking through this summary, to the best of my knowledge and belief there is no deliberate shilling. As this is free documentation in support of free software, I can attest to no funding, bribery or insider trading bias as well. Smiley. I will also attest to the belief that Unicon is awesome. You should use it for as many projects as possible, and not feel any regret or self-doubt while doing so. Double smiley.
With that out of the way, here is a recap:
Unicon translated to icode is nearly equivalent to Python and Elixir in terms of the timing (variants occur between runs, but within a few tenths or hundredths of a second difference, up and down).
C wins, orders of magnitude faster than the scripted language trials and marginally faster than most of the other compiled trials.
A later addition of gcc -O3 compiles and an Assembler sample run faster,
but that counts as fretting [4].
The GnuCOBOL, gfortran, GNAT/Ada and BaCon programs fare well, only a negligible fraction slower than the baseline C. Both GnuCOBOL and BaCon use C intermediates on the way to a native compile. gfortran uses the same base compiler technology as C in these tests (GCC). Unicon can load any of these modules when pressed for time.
D also fares well, with sub tenth of a second timing.
Java and Gforth test at a third as fast as C, admirable, neck and neck with Vala and Genie. Nim, PHP and Rust clock in shortly after those timings.
Unicon compiled via -C completes roughly 4 times faster than the
icode virtual machine interpreter version, at about 1/10th C speed.
Ruby, Perl and Neko, are faster than interpreted Unicon for this sample.
Elixir clocks in next and like Python, pretty close to the bar set by interpreted Unicon.
REBOL and REXX clock in just a little slower than the Unicon mark.
Python and Elixir perform this loop with similar timings to interpreted Unicon, all within 2% of each others elapsed time. Widening the circle a little bit, REXX and REBOL become comparable as well. Revealing a bit of the author’s bias, let’s call these the close competition while discussing raw performance. I have a different (overlapping) set of languages in mind when it comes to overall competitive development strategies [7].
Tcl takes about twice as long as Unicon when using the JimTcl interpreter, and approaching 9 times slower with a full Tcl interpreter. Gjs ended up timing in between the two Tcl engines.
ALGOL, S-Lang, Smalltalk and SNOBOL also took about twice as long as Unicon when running this trial.
Duktape ran at second to last place, just over a minute.
bash was unsurprisingly the slowest of the bunch, approaching a 5 minute run time for the 16.8 million iterations.
Native compiled Unicon timing is on par with Ficl, and a little faster than Lua, node.js, and then Guile, but still about 10 times slower than the compiled C code. (Unicon includes automatic detection of native integer overflow, and will seamlessly use large integer support routines when needed. Those tests will account for some of the timing differences in this particular benchmark when compared to straight up C).
Once again, these numbers are gross estimates, no time spent fretting over how the code was run, or worrying about different implementations, just using the tools as normal (for this author, when not fretting [4]).
Unicon stays reasonably competitive, all things considered.
| Scale | Languages |
|---|---|
| <1x | Assembler, -O3 C |
| 1x | C, Ada, BASIC, COBOL, D, Fortran, Unicon loadfunc |
| 3x | Java, GForth, Vala, Genie |
| 6x | Nim, PHP, Rust |
| 10x | Unicon -C |
| 15x | Ficl, Lua, Scheme |
| 20x | Neko, Node.js |
| 25x | Perl, Ruby |
| 40x | Unicon, Elixir, Python, REBOL, REXX |
| 100x | Algol, JimTcl, S-Lang, Smalltalk, SNOBOL |
| 200x | Gjs |
| 350x | Tcl |
| 1200x | Duktape |
| 5600x | Shell |
The Unicon perspective¶
With Unicon in large (or small) scale developments, if there is a need for speed, you can always write critical sections in another compiled language and load the routines into Unicon space. The overhead for this is minimal in terms of both source code wrapper requirements and runtime data conversions[5]. The number of systems that can produce compatible loadable objects is fairly extensive; C, C++, COBOL, Fortran, Vala/Genie, Ada, Pascal, Nim, BASIC, Assembler, to name but a few. This all means that in terms of performance, Unicon is never a bad choice for small, medium or large projects. The leg up on development time may outweigh a lot of the other complex considerations.
A note on development time¶
With a program this short and simple minded, development time differences are negligible. Each sample takes a couple of minutes to write, test and document [6].
That would change considerably as problems scaled up in size. Not just in terms of lines of code needed, but also the average time to get each line written, tested and verified correct.
General know how with each environment would soon start to influence productivity and correctness, and bring up a host of other issues. A lot can be said for domain expertise with the language at hand. Without expertise, development time may extend; referencing materials, searching the ecosystem for library imports, becoming comfortable with idioms, with testing and with debugging.
The less lines that need to be written to solve tasks can add up to major benefits when comparing languages in non-trivial development efforts.
| [2] | (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11) Due to the length of the timing trials, some results are not automatically captured during documentation generation. Results for those runs were captured separately and copied into the document source. All other program trials are evaluated during each Sphinx build of this document (results will vary slightly from release to release). |
| [3] | The bar chart graphic was generated with a small Unicon program. |
| [4] | (1, 2, 3) Ok, I eventually fretted. Added loadfunc() to show off mixed programming for speed with Unicon. Also added -O3 gcc timing and an assembler sample that both clock in well under the baseline timing. |
| [5] | There are a few examples of how much (little) code is required to wrap compiled code in Unicon in this docset. See libsoldout markdown for one example, wrapping a C library to perform Markdown to HTML processing in about 30 lines of mostly boilerplate source. Other entries in the Programs chapter exercise and demonstrate the loadfunc feature that allows these mixed language integrations. |
| [6] | (Except for the BaCon trial). That example stole a few extra minutes
for debugging, out of the blue, many days after the initial code writing
and verification pass. It turns out BaCon generated a temporary
Makefile during its translation to C phase, and I had to track
down the mystery when an unrelated Makefile sample kept
disappearing during generation of new versions of this document. That led
to moving all the performance samples to a separate sub-directory to avoid
the problem, and any others that may occur in the future when dealing with
that many programming environments all at the same time and in the same
space. BaCon was fixed the same day as the inconvenience report. |
| [7] | Not to leave you hanging; I put C, C++, C#, Erlang, Go, Java, Lua, Node.js, Perl, Python, PHP, Red, and Ruby firmly in the Unicon competitive arena. Bash/Powershell and Javascript count as auxiliary tools, that will almost always be mixed in with project developments. Same can be said for things like HTML/CSS and SQL, tools that will almost always be put to use, but don’t quite count as “main” development systems. For Erlang, I also count Elixir, and for Java that includes Scala, Groovy and the like. I live in GNU/Linux land, so my list doesn’t include Swift or VB.NET etc, your short list may differ. I also never quite took to the Lisp-y languages so Scheme and Closure don’t take up many brain cycles during decision making. And finally, I’m a huge COBOL nerd, and when you need practical programming, COBOL should always be part of the development efforts. |
Development time¶
Even though execution time benchmarking is hard to quantify in an accurate way (there are always issues unaccounted for, or secrets yet to uncover) and is fraught with biased opinion[8], judging development time is magnitudes harder. Sometimes lines pour out of fingers and code works better than expected. Sometimes an off by one error can take an entire afternoon to uncover and flush productivity down the toilet.
In general, for complex data processing issues, very high level languages beat high level languages which beat low level languages when it comes to complete solution development time. It’s not a hard and fast rule, but in general.
Unicon counts as a very high level language. There are features baked into
Unicon that ease a lot of the day to day burdens faced by many developers.
Easy to wield data structures, memory managed by the system and very high
level code control mechanisms can all work together to increase productivity
and decrease development time. In general. For some tasks, Ruby may be
the better choice, for others tasks Python or C or Tcl, or some
language you have never heard of may be the wisest course. Each with a
strength, and each having skilled practitioners that can write code faster in
that language than in any other.
Within the whole mix, Unicon provides a language well suited to
productive, timely development with good levels of performance. Other
languages can be mixed with Unicon when appropriate, including loadable
routines that can be as close to the hardware as hand and machine optimized
assembler can manage.
If the primary factor is development time, Unicon offers an extremely competitive environment. The feature set leaves very few domains of application left wanting.
Downsides¶
Unicon has a few places that can expose hard to notice construction problems.
Goal-directed evaluation can spawn exponential backtracking problems when two or more expressions are involved. Some expression syntax can end up doing a lot more work in the background than it would seem at a glance. Bounded expressions (or lack thereof) can cause some head scratching at times.
There are tools in place with Unicon to help find these issues, but nothing will ever beat experience, and experience comes from writing code, lots of code.
Luckily, Unicon is at home when programming in the small as it is with middling and large scale efforts[9]. The class, method, and package features, along with the older link directive make for a programming environment that begs for application. There are a lot of problem domains that Unicon can be applied to, and that can all help gaining experience.
Due to some of the extraordinary features of Unicon, it can be applied to very complex problems[10]. Complex problems always shout out for elegant solutions, and that lure can lead to some false positives with initial Unicon programs. It can take practice to know when an edge case is not properly handled, or when a data dependent bug sits waiting for the right combination of inputs to cause problems. Rely on Unicon, but keep a healthy level of skepticism when starting out. This is advice from an author that is just starting out, so keep that in mind. Read the other Technical Reports, articles, and Unicon books; as this document is very much entry level to intermediate Unicon. Wrap expressions in small test heads and throw weird data at your code. Experiment. Turn any potential Unicon downsides into opportunities.
| [8] | (1, 2) With biased opinions comes cognitive filtering. While writing the
various tightloop programs, I wanted Unicon to perform well in the
timing trials. That cognitive bias may have influenced how the results
were gathered and reported here. Not disappointed with the outcomes, but
C sure sets a high bar when it comes to integer arithmetic. |
| [9] | Having no actual experience beyond middling sized projects, I asked the forum if anyone has worked on a large Unicon system with over 100,000 lines of code. Here are a couple of the responses: The biggest project I worked on using Unicon was CVE (http://cve.sourceforge.net/) not sure if we broke the 100,000 LOC [mark] though. I don’t see any reason why you can’t write large projects using Unicon. With the ability to write very concise code in Unicon, I’d argue it is even easier to go big. –Jafar The two largest known Unicon projects are SSEUS at the National Library of Medicine, and mKE by Richard McCullough of Context Knowledge Systems, not necessarily in that order. They are in the 50-100,000 lines range. CVE approaches that ballpark when client and server are bundled together. Ralph Griswold used to brag that Icon programs were often 10x smaller than corresponding programs in mainstream languages, so this language designed for programs mostly under 1,000 lines is applicable for a far wider range of software problems than it sounds. While Icon was designed for programming in the small, its size limits have gradually been eliminated. Unicon has further improved scalability in multiple aspects of the implementation, both the compiler/linker and the runtime system. In addition, Unicon was explicitly intended to further support larger scale software systems, and that is why classes and packages were added. Clint Those quotes don’t answer all the questions, like what maintainers go through, or how long it takes new contributors to get up to speed, but as anecdotes, I now feel quite comfortable telling anyone and everyone that Unicon is up to the task of supporting large scale development and deployments, along with the small. |
| [10] | I once overheard a C++ engineer with a problem distilling a Grady/Booch style Rapid Application Development system output into a usable API for the project at hand. (I was programming a Forth system that was being upgraded as part of the C++ project, working in the same office space (the big rewrite flopped eventually)). There was a Tcl/Tk prototype ready for user screening but no easy way of getting smooth data flow across systems, due to the utterly complex cloud diagrams to C++ class data interactions. 1995 timeframe. Icon, a one day development effort, decoding the RAD binaries and text, creating templated sources in C++, Forth, Tcl/Tk (all of it simplified, as a prototype) with surprisingly accurate (to those experiencing first exposure to Icon) data sub fielding in drop downs linked to recursive sub lists. Ok, two days, and an all nighter; from the middle of one working day until near the end of the next, to a working demo. Source code all generated by an Icon translator from RAD to programming languages, data access names, structures, all synced for inter-system transfer. RAD to C++, Forth, Tcl/Tk; thanks to Icon. I had overheard and then bragged that their Grady/Booch project plan wasn’t too big or complex for Icon version 6; then had to deliver. There was motivation with nerd points at stake. Icon shone, but no one really noticed. Management was more impressed by having (prototype) GUI screens with data connectivity for the big project than how it was developed overnight, leveraging goal directed evaluation, string scanning, and utterly flexible Icon data structures. And yes, further use uncovered some interesting hot spots when it came to performance. Learning done the hard way. Implicit back tracking can lead to unnecessary cycles if some care is not shown when nesting conditionals; for instance, the choice of early truth detection in loops can mean the difference between impressing the team, or losing nerd cred on bets and brags. It is worth spending some time with Unicon profiling, and memory map visualization. http://www2.cs.arizona.edu/icon/docs/docs.htm Get used to the feel of common case decision order for tests across a set of fields in an application. It takes practise when trying to shave branches off a decision tree (or to avoid computing completely new forests needlessly). There will likely be some hard to figure out fails when gaining wisdom in Unicon, but the language can handle extremely complicated data mashing, with flair; and should be used so, repeatedly. |
Unicon Benchmark Suite¶
There is a Technical Report (UTR16a) 2014-06-09, by Shea Newton and Clinton
Jeffery detailing A Unicon Benchmark Suite
http://unicon.org/utr/utr16.pdf and sourced in the Unicon source tree under
doc/utr/utr16.tex.
The results table shows that unicon runs of the benchmarks range from
345.2x(n-bodycalculation) to1.6xfor thethread-ringtrial, compared to the C code baseline timings.
uniconc compiled versions range from
57.9x(n-body) to0.6x(regex-dna) of the C baseline.
Uniconc increasing the n-body run speed by a factor of 6 compared to
the icode interpreter. The regex-dna trial actually ran faster with
Uniconc than in C. Take a look at the TR for full details.
With another caveat; runtime vs development time. There should be a column in any benchmark result sheet that quantifies the development time to get correctly functioning programs. I’d wager that Unicon would shine very bright in that column.
run-benchmark¶
You can run your own test pass in the tests/bench sub-directory of the source tree.
prompt$ cd tests/bench
prompt$ make
prompt$ ./run-benchmark
A local pass came up looking like
prompt$ make
...
./generate
generating input files.............done!
prompt$ ./run-benchmark
Times reported below reflect averages over three executions.
Expect 2-20 minutes for suite to run to completion.
Word Size Main Memory C Compiler clock OS
64 bit 7.272 GB gcc 5.4.0 3.4 GHz UNIX
CPU
4x AMD A10-5700 APU with Radeon(tm) HD Graphics
Elapsed time h:m:s |Concurrent |
benchmark |Sequential| |Concurrent| |Performance|
concord concord.dat 3.213 N/A
deal 50000 2.469 N/A
ipxref ipxref.dat 1.345 N/A
queens 12 3.554 N/A
rsg rsg.dat 2.815 N/A
binary-trees 14 5.172 7.736 0.668x
chameneos-redux 65000 N/A 5.706
fannkuch 9 3.601 N/A
fasta 250000 3.174 N/A
k-nucleotide 150-thou.dat 5.153 N/A
mandelbrot 750 13.877 7.662 1.811x
meteor-contest 600 4.793 N/A
n-body 100000 4.326 N/A
pidigits 7000 2.903 N/A
regex-dna 700-thou.dat 4.231 3.452 1.225x
reverse-complement 15-mil.dat 4.828 N/A
spectral-norm 300 3.469 N/A
thread-ring 700000 N/A 6.460
To compare (and take part) visit http://unicon.org/bench
If there are no results for your particular machine type and chipset on the Accumulated Results chart, Clinton Jeffery collects summaries with information on how to report them at
http://unicon.org/bench/resform.html
The makefile creates some fairly large test files, so you’ll probably want to clean up after running the benchmark pass.
prompt$ make clean
prompt$ rm *-thou.dat *-mil.dat ipxref.dat
Unfortunately, make clean does not remove the benchmarking data files.
Index | Previous: Execution Monitoring | Next: Icon Program Library

{kind=link}